Get Kafka in prod-ready, 2 decisions to make and 3 implementation details¶

Kafka is a well-known event-streaming solution that provides events publish/subscribe stream and persistence. Besides the main strength, very high throughput (approximate million RPS), Kafka also does well on scalability and availability and provides guarantees on event broadcasting.
But Kafka can’t be just plugged into our system and bring out 100% of its advantages. So in this article, we will go through 2 decisions and 3 implementation details that should consider when using Kafka in Production. The Decisions to make include:
- number of partitions and replicas
- semantic level.
Besides, we should be careful in the following issues:
- eventually consistency
- event order
- handling retry and recovery.
Before this, let’s have a basic recap of Kafka!
Basic recap¶
Kafka mainly provides an asynchronous decouple way for different web applications. We Can divide it into the server and client sides, the server side is usually a cluster that receives and stores events from the client. The client side’s responsibility is to send/consume events from the server and do the business logic among events. See the official document for a detailed introduction.
Basic Terminology¶
For the Kafka server-side, we have:
- Broker
Broker is a single Kafka server to receive/reply to event messages. We can connect multiple brokers to form a Kafka cluster. - Topic
The Topic is for distinguishing all event messages sent into Kafka (like the table in RDB) - Partition
One Topic will be divided into multiple partitions to store the event message of the same topic. - Replica
One Topic can have multiple data replicas on different brokers.
Given there are 3 partitions and 3 replicas for one topic in a 3 brokers Kafka cluster. Then there will be 3 partitions for each broker for this topic, and one of the same partitions will be selected as the Leader while others are replicas (as in the image below).
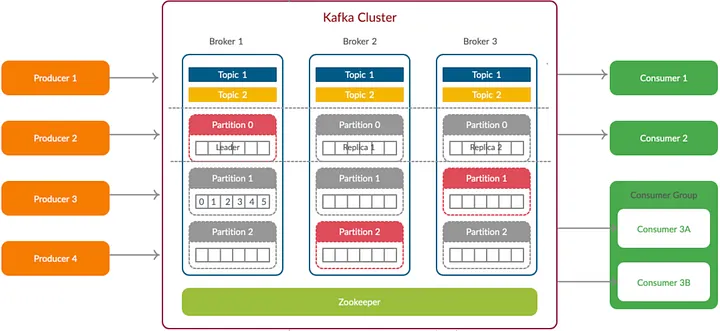 (image copied from https://learnbyinsight.com/2020/07/26/beginner-guide-to-understand-kafka/)
(image copied from https://learnbyinsight.com/2020/07/26/beginner-guide-to-understand-kafka/)
Here we skip the Zookeeper since the Kafka team seems to discard it and use the Quorum controller instead.
The Kafka client-side includes:
- Producer
The producer sends data to the broker that has the leader partition of the topic. - Consumer
The consumer pulls data from the broker that has the leader partition of the topic by default (may read from replicas partition, see this article). - Consumer group
We can assign multiple consumers to one consumer group, then one of them will pull it, while others do not when one event message is sent, but the consumer outside the same consumer group will consume the event message.
Decision 1: number of partitions and replicas¶
Before we start to use Kafka in our system, the first thing is to create the topic in the Kafka cluster with parameters like the number of partitions and replicas, which affect the performance and reliability respectively. Since the partition represent the parallelism
number of partitions¶
For partitions, there are two aspects to consider, the desired throughput and the number of brokers and consumers. Before that, we should know that 1 partition can only be consumed by 1 consumer in a consumer group. The exceed consumers will be idle, but two partitions can be listened to by the same consumer. First, the number of partitions must be greater than the number of consumers.
Second, we should do a simple test about the speed for consuming from a single partition, and use the speed to measure the number with the desired throughput.
Finally, we should modify it according to the number of brokers, because partitions should be evenly distributed to each broker in order to get a balanced loading on each broker. So here is some advice, when there are fewer than 6 brokers, then we should create the partitions with 2 or 3 times the number of brokers in the cluster. The exceeded partitions are for expanding cluster size (which can be done with help of the partition reassignment tool). And if there are more than 6 brokers, we can use the same number of brokers.
number of replicas¶
Before we start, there are two properties that need to be clarified here, min.insync.replicas and acks. The former restricts the minimum number of replicas that have the same message as the leader partition; the latter denotes the number of replicas “receive” the produced message. this article describes these in every detail.
For replication, it is relatively simple since it is just a trade-off between performance and fault tolerance. In almost every distributed system, 3 replication is a best practice in common. Since it provides strong reliability, for example, when one of the partitions is dead, then we still have two insync-replicas and plenty of time to recover the failed replica or start a new one. The key point is that one more fail is tolerable when recovering the third replica, the Kafka remains available except there are three fails before recovering one of them. Moreover, the more replicas the more acknowledgment the producer needs when publishing an event (if the acks is set to all), which is a performance killer. So I believe that 3 is the best number for replicas.
But for the min.insync.replicas, I think it can remain at 1 for higher availability as Cloudkarafka recommended. Since if set to 2, then we will have a situation where only one broker is down, but the whole cluster is not able to receive new messages, which I think is not reasonable.
Decision 2: Semantic level¶
Below are the message semantic levels in the official document:
- At most once — Messages may be lost but are never redelivered.
- At least once — Messages are never lost but may be redelivered.
- Exactly once — this is what people actually want, each message is delivered once and only once.
This issue is all about the retry/acknowledge/idempotent mechanism of the producer and consumer and once again, is a trade-off between performance and completeness guarantee. Below, I use a simple table to display how to achieve the semantic level:

At most once¶
When the producer is set to no retry and ack is needed, then it is obvious that there might be no message sent to Kafka. Besides, the consumer enable.auto.commit is true (as default) when it pulls the message from a broker before really handling it successfully, so maybe all the consumption process fails which leads to “At most one” message being processed.
At least once¶
When the producer starts to retry until receives at least one ack from the broker, it might send 1 or more times for the same message (>1 due to a network error). Since the target is that the message is processed “at least once”, we should no longer use auto-commit ack, but manually commit it after the process successfully instead.
Exactly once¶
Based on settings of “At least once”, we can add idempotent mechanics to achieve exactly once. want to do so, we can add a property like enable.idempotence to true in producer (note: need acks=all), which will append a PID and sequenceId in the sent and retry event message to make the broker can identify which message is already written into the partition. As a result, the producer will only make one record in Kafka.
In the consumer, we must implement our business logic in an idempotent way, in order that the manual return ack is not received by the broker due to a network error. An easy implement way is to add a eventId in the event message, then use it as an idempotentKey or dataVersion to prevent reprocessing of the same event.
Implement Detail 1: Eventually consistency¶
There are two layers of eventually-consistency for using Kafka,
- Produce event eventually received by all replicas.
- All consumer groups eventually pull and processed the event
In the producer, this is a trade-off of performance since we can set the number of acks that the producer needs. The options include 0, 1, and all, the higher number causes lower RPS of the whole system.
We should always be aware that the consumer is not guaranteed to finish consuming the event after servers received a request and success sent an event to Kafka and then respond with an “ok” back to the client. Especially when the second request comes, and we need to check the data which should be updated by the consumer when handling the first event, like an event-sourcing system. We can add the version checks by adding an eventId in the event message when we encounter this situation.
Implement Detail 2: Event Order¶
In Kafka, only the events from the same partition are guaranteed to be consumed in order, but it’s impossible to use only one partition that will completely lose the parallelism ability (if really need to do so, I would say that the scenario is not suitable for using Kafka).
So, the problem becomes how to let the order-sensitive events can be in the same partition. There are three ways to decide which event would be sent to which partition:
- Round robin (Default)
In this way, the event will be sent to all partitions in balance. - Hash key
In this way, all events should contain a key, which will be hashed and distributed into each partition. But we need to be aware of the loading of each partition. As we can see the default hash method takes modulus by the number of partitions, so we basically need to make sure that the event needs orders must have the same key; and irrelevant events should have a different key to make a balanced loading. - Custom partitioner
If we need a more complex logic than the hash key method to satisfy our business, then we should implement a custom partitioner and config it in the consumer. Here is an easy example of doing this.
This section gives a brief concept about event ordering, we can learn more and check the implementation example in this article.
Implement Detail 3: Handle retry and recovery¶
As an asynchronous messaging system, error handling is an important part of providing a reliable service. Especially for the consumer of Kafka, imagine that if the consumer encounters an exception (from DB or third-party API), the behavior will differ depending on the settings of ack commitment.
- auto-commit = true
The consumed event is committed before catching the exception, so the event actually is considered finished. No consumer will try to consume that event again, which will lead to data inconsistency. - auto-commit =false
The consumed event is committed manually, so our code will decide whether the exception is thrown before or after catching an exception, in most cases we commit the event after all processes are done. Therefore, it will cause an infinite loop of consuming events and catch exceptions (if it’s not a temporary issue).
It seems to get a bad result under both settings when an exception occurs. So it’s important to implement the retry and recovery mechanism. The concepts and steps are like following:
- consume event
- send to retry-queue (delay-queue) if a recoverable exception is thrown
- send to fail-queue (dead letter queue) if a non-recoverable exception is thrown
- consume from retry-queue
- send to fail-queue if it fails again
- consume from fail-queue and log/alert
First, our work is to define whether an exception is recoverable or not. we can reference this article which defines many error scenarios. Second, we should decide that the retry-queue and fail-queue would be implemented by another Kafka topic or DB table…etc. I think there is no correct answer, we should choose the service which provides the highest availability. Finally, it’s time to implement the mechanism, we can take a look at my article about how to do that in a Spring Boot 3 application.
Conclusion¶
There are plenty of articles that dive deep into the topic in this article, but this article tries to summarize them and organize the key points we need to decide and design when we want to use Kafka in our system in the real environment. Using Kafka in a real environment means it needs to have high reliability and availability, and also provide high throughput (achieve an acceptable balancing performance, at least).
Reference¶
Basic introduction document
- https://kafka.apache.org/documentation/
- https://learnbyinsight.com/2020/07/26/beginner-guide-to-understand-kafka/
Consume from replicas
Kafka cluster without Zookeeper
The number of partitions and replicas
- https://www.conduktor.io/kafka/kafka-topics-choosing-the-replication-factor-and-partitions-count
- https://www.linkedin.com/pulse/choosing-right-partition-count-replication-factor-apache-ul-hasan/
Semantic level
- https://medium.com/@andy.bryant/processing-guarantees-in-kafka-12dd2e30be0e
- https://medium.com/lydtech-consulting/kafka-idempotent-producer-6980a3e28698
Event order
Error Handling